
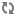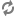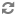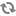
Putting it All Together: spark-defaults.conf
Combining the performance settings for
ORC and Parquet input, produces the following set of options
to set in the spark-defaults.conf file for Spark applications.
spark.hadoop.fs.s3a.experimental.input.policy random
spark.sql.orc.filterPushdown true
spark.hadoop.parquet.enable.summary-metadata false
spark.sql.parquet.mergeSchema false
spark.sql.parquet.filterPushdown true
spark.sql.hive.metastorePartitionPruning trueWhen working with S3, the S3A Directory committer should be enabled for both performance and safety:
spark.hadoop.fs.s3a.committer.name directory
spark.sql.parquet.output.committer.class org.apache.spark.internal.io.cloud.BindingParquetOutputCommitter
spark.sql.sources.commitProtocolClass org.apache.spark.internal.io.cloud.PathOutputCommitProtocol